In mid-April, I found myself up late on a Saturday night working away on enhancements to my WP Practice system, when I accidentally nuked one of my development environments. Fun ensued.
I was building an enhancement to the “Delete account” functionality offered to patients (part of GDPR features). I built the original functionality quickly and it worked fine, but I felt there was a risk of patients “accidentally” deleting their own accounts.
Left: a “cool down” implementation. The “Delete account” button can’t be clicked for ten seconds after the modal is shown. Idea was to force the user to pause and check before trying to proceed.
After getting everything working correctly, I went off to bed. The next morning, without thinking, I pressed the “Delete account” button that was still on-screen from the night before (I still don’t know exactly why I did this, must have been some autopilot from clicking the button so many times the previous evening). So, in an awful stroke of irony, I had deleted my “user 1” account using the system as implemented above.

The feeling was made worse as I thought I’d somehow caught it by pressing the “stop loading” button and going to the dashboard (which loaded fine), but one refresh later, I was redirected to the homepage, and found virtually all of the content gone. Great, I’ve borked my development installation that has a huge amount of useful test content and configurations.
I knew that I had configured my systems to do automated backups, and could see them all in the AWS console as I was building the services, but I’d never actually tried a restore from them.
How did you get the data back then?
Glad you asked. Below, I’ve outlined the steps I took to get the data into a readable format. It’s a bit wacky, but I couldn’t find a high level end-to-end guide for getting data out of RDS snapshots. If this helps someone out there, great. If not, well, good luck with the next click? ¯\_(ツ)_/¯. Worth noting, there’s maybe a better process out there too, if you happen to know about one, please do let me know!
Heads up! There may be charges applied to your AWS billing for some of the systems / processes I’ve used here.
I had previously configured the RDS server to do a daily snapshot, so there would be something to fall back on in the case of something going wrong somewhere. Up until doing this process, I had never done it before.
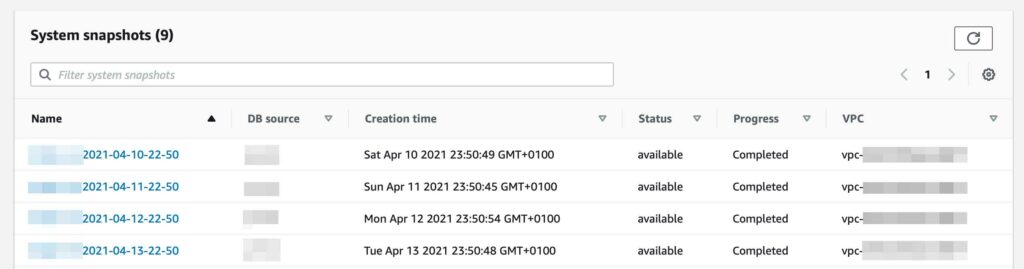
Great, snapshots seem to have worked as configured. I have a backup of the database from the previous evening, so I go into it and locate a handy “Export to Amazon S3” button.
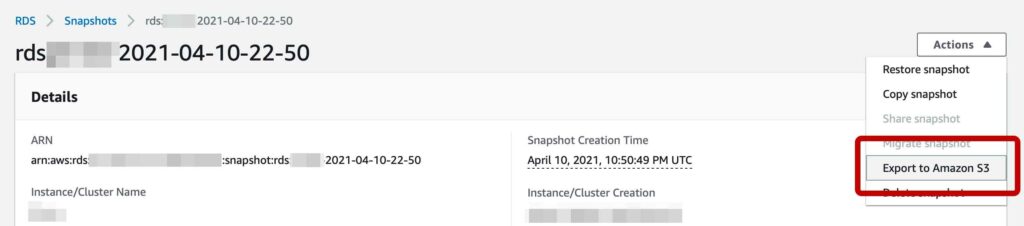
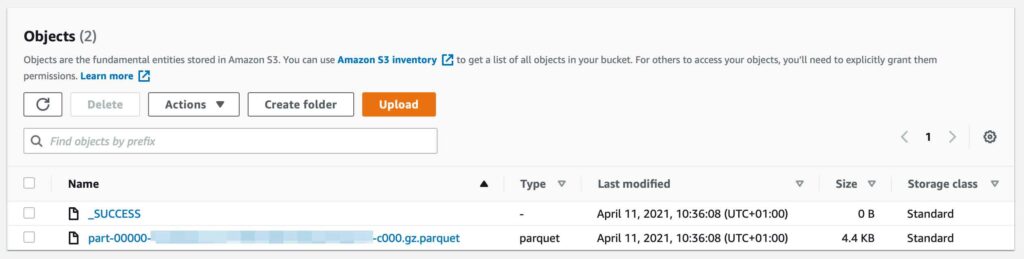
At this stage I was hoping to locate something like an .sql or .zip file in S3, but instead I was greeted with an Apache Parquet file… not what I expected at all. After figuring out a little more about Parquet, I found myself in a bit of a pickle – I had no idea how to extract the data.
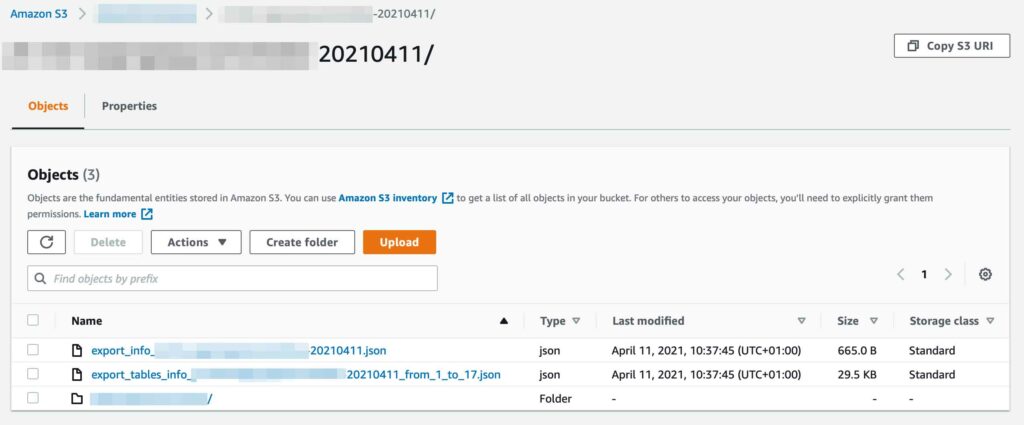
From the screenshot above, we can see a couple of JSON files containing information about the dataset outputted from the RDS service, then a folder containing further folders of each table in the dataset.
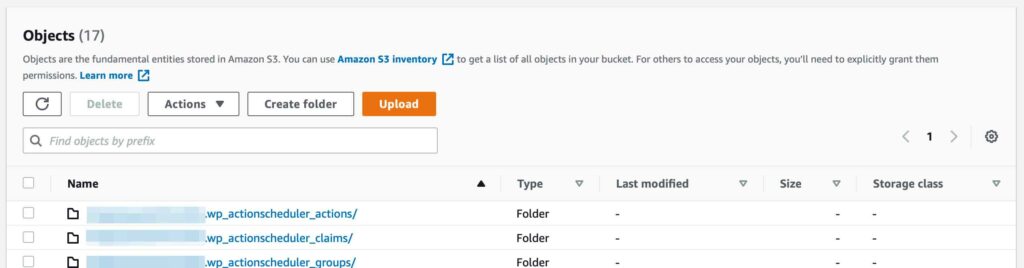
Within each of these directories again, a single .gz.parquet file exists along with a result status file.
From S3 into AWS Athena via AWS Glue
The next step was to make use of another AWS service “AWS Glue” to get the data into another AWS service: “Athena”. Glue allows me to crawl data stored in S3, parse it, and then reconstruct the dataset in AWS Athena. Athena is a query interface for working with datasets within S3.
I configured a new on-demand crawler in Glue that would go to my S3 store, crawl the directories created by the RDS export, and then re-assemble a database inside the Athena service.
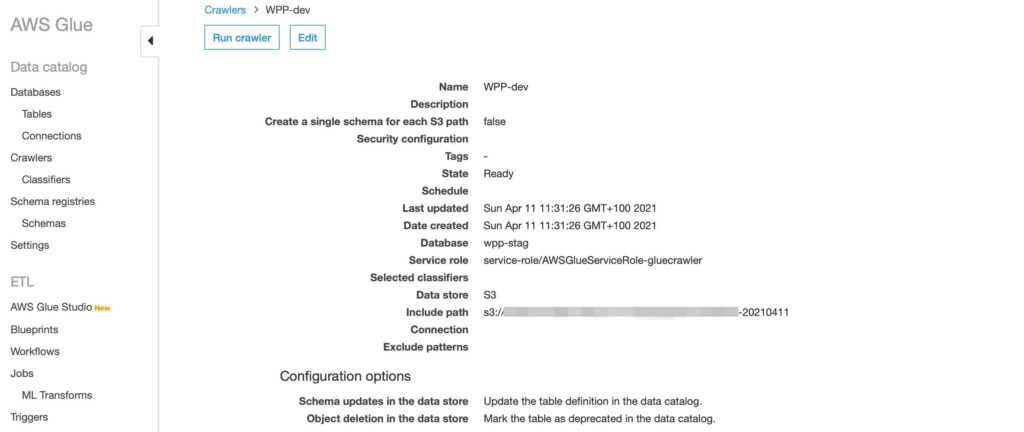
Once the crawler ran, it created a new database within AWS Athena that I could then query using the service.
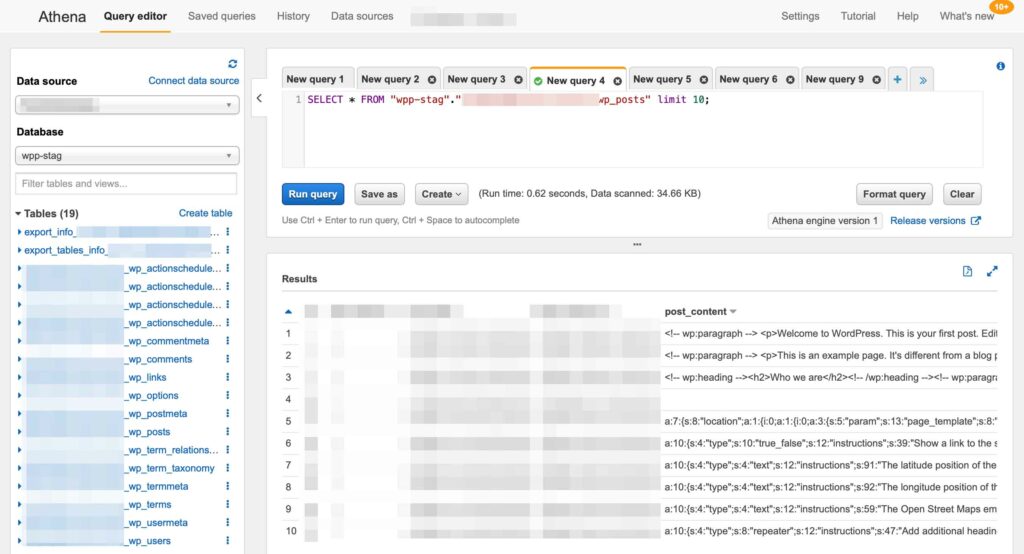
Got it! There’s an “Export to CSV” link at the top of the results, I was able to transform the data and get it back into a .SQL format. Then it’s time to start getting it pulled back into the database, when suddenly the error console starts filling up.

Turns out the post data was never gone at all, just unpublished when the user was removed. Once I restored the user, I was able to re-publish all content and everything was back to normal. The whole process was a pointless exercise, but hey, I learned stuff.
Lessons learned
- Have code-level protections against deleting important things
- As in, “user one should never be deleted so don’t you dare delete it”
- The system has also been expanded to prevent practice staff deleting their accounts too
- Do a proper post-mortem before diving into trying to fix a problem
- Maybe actually practice disaster recovery before it’s needed in the real world
- AWS really can do anything
Bonus round
In an effort to make it even more challenging to accidentally delete an account, I settled on the design below. I’ve seen this pattern used before in some services when you’re about to do something particularly destructive.
Rather than using a timer-based cool down, I used a “type to confirm” system. A user needs to explicitly type “delete my account” for the button to be enabled.
The text will also auto-clear after 120 seconds.
Just in case.